
Tu viens d’implémenter ton balisage, tu attends les étoiles dans la SERP — et rien. C’est le scénario classique, et il est bien plus fréquent qu’on ne le croit. Un test schema org fait en amont t’aurait probablement évité ça. Le problème, c’est que les erreurs de balisage ne crient pas. Pas d’alerte rouge, pas de message d’erreur visible, pas de page qui disparaît. Le site tourne, le contenu s’affiche — mais les rich snippets, eux, ne se déclenchent jamais. En fait, la plupart des propriétaires de site découvrent le problème des mois plus tard, souvent par hasard, en cherchant autre chose. D’ailleurs, ce n’est pas une question de compétence : c’est une question de méthode. Sans validation systématique, tu peux investir du temps dans un balisage irréprochable en apparence, et ne jamais en voir le moindre bénéfice en termes de visibilité.
Pourquoi les erreurs Schema.org passent inaperçues

Aucune alerte ne s’affiche dans la SERP quand ton balisage est cassé. Google ne va pas t’envoyer un signal visible pour te signaler qu’il ne peut pas interpréter tes données structurées. La page continue de s’indexer, le contenu reste accessible — mais les informations additionnelles que tu espérais voir apparaître, étoiles d’avis, fil d’Ariane, prix, restent absentes des résultats.
Du coup, le risque est doublement pernicieux : tu ne le vois pas, et tu ne le ressens pas immédiatement. Sur certaines requêtes, un balisage correct peut générer entre 12 et 35% de taux de clic supplémentaire. Un champ manquant, une propriété mal placée, et ce gain est réduit à zéro — sans que personne ne le remarque pendant des semaines.
Il y a aussi une nuance que beaucoup oublient : syntaxe correcte ne veut pas dire reconnaissance par Google. Tu peux avoir un code propre, sans erreur HTML, et pourtant placer un schéma Product sur une page qui n’en propose pas réellement. Aucune alerte ne sera levée. Mais le rich snippet ne sera jamais activé.
Les fausses impressions de conformité, c’est ça le vrai danger.
Comparer les outils : Rich Results, Validator, Screaming Frog
Partir de ce constat d’invisibilité, c’est comprendre pourquoi aucun outil seul ne suffit. Chaque solution répond à un besoin différent, à une étape différente du diagnostic.
Le Google Rich Results Test est la référence quand tu veux savoir si une page est éligible aux résultats enrichis dans Google. La réponse est directe : oui ou non. Son avantage, c’est qu’il simule le filtre réel de Google — et ce filtre n’utilise qu’une partie du vocabulaire Schema.org. Du coup, il peut ignorer des balisages techniquement valides mais non reconnus pour la Search. Sa limite principale : une analyse page par page, inutilisable pour auditer un site de plusieurs milliers d’URLs.
Le Schema.org Validator couvre l’ensemble du standard, bien au-delà de ce que Google exploite. Il détecte des erreurs syntaxiques et sémantiques que l’outil Google ne signale pas. En fait, c’est précisément là que réside son piège : un schéma valide pour Schema.org n’est pas forcément interprété par Google pour activer un rich snippet. Il peut induire une fausse confiance si on s’y arrête.
Screaming Frog joue dans une autre cour. C’est un outil de crawl, pas un validateur sémantique. Il scanne des milliers de pages, remonte les absences de balisage, détecte les incohérences à l’échelle d’un site entier. C’est indispensable pour une refonte ou un audit régulier. Mais il reste moins précis sur la qualité sémantique ou l’éligibilité réelle côté moteur.
| Outil | Points forts | Limites | Cas d’usage | Tarif |
|---|---|---|---|---|
| Google Rich Results | Validation officielle, proche de la réalité SERP | Page à page, focus Search uniquement | Validation pré/post-déploiement | Gratuit |
| Schema.org Validator | Large couverture, détection fine des erreurs | Ne garantit pas l’activation des rich snippets | Conformité technique et sémantique | Gratuit |
| Screaming Frog | Audit complet, détection massive, vision site | Validation limitée à la présence technique | Audit régulier, refonte globale | Freemium |
D’ailleurs, la bonne pratique, c’est de les alterner selon l’étape : Validator en préproduction, Rich Results Test après mise en ligne, Screaming Frog pour la couverture globale. Aucun des trois ne fait le travail des deux autres.
Ce que les outils ne détectent pas

Même en combinant les trois outils, il reste une catégorie entière d’erreurs qui passe au travers. Les validateurs ne jugent pas la logique. Ils vérifient la forme, pas le fond.
Premier cas typique : un schéma syntaxiquement parfait, mais sémantiquement absurde. Placer un schéma « Recipe » sur une page qui ne contient aucune recette va passer tous les tests techniques sans problème. Google, lui, ne déclenchera rien.
Deuxième problème fréquent : les champs obligatoires renseignés avec des valeurs vides ou génériques. Un aggregateRating présent dans le code mais sans données réelles ne lèvera aucune alerte. En fait, c’est exactement ce qui se passe lors d’implémentations dynamiques où des valeurs par défaut sont injectées faute de contenu spécifique. L’outil valide la structure. La SERP, elle, n’affiche rien.
Il y a aussi la question de cohérence entre le balisage et ce qui est réellement visible sur la page. Google compare de plus en plus ces deux éléments. Si tes données structurées indiquent une note de 4,9 étoiles et que ta page n’affiche aucune notation visible, le rich snippet peut être désactivé du jour au lendemain.
Aucun validateur automatique ne capte ces incohérences métier.
Du coup, la conclusion s’impose : le diagnostic final exige toujours une relecture humaine. Une vérification de l’adéquation entre ce que le schéma dit et ce que la page montre vraiment. C’est une question de bon sens autant que de technique.
Checklist de test avant déploiement
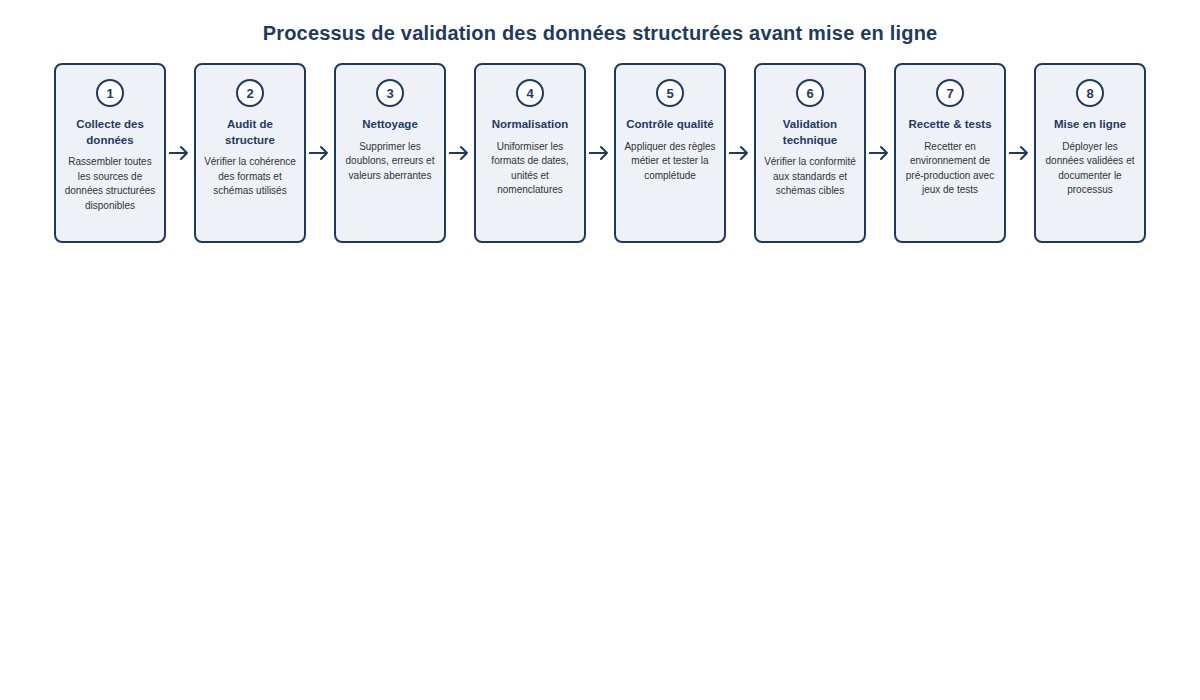
Une bonne méthode, c’est un process reproductible. Sans ça, chaque mise à jour expose le site à une régression silencieuse.
Voici la séquence à appliquer avant toute mise en ligne :
- Tester la conformité syntaxique sur Schema.org Validator en préproduction.
- Vérifier que le type de schéma choisi correspond réellement au contenu de la page.
- Contrôler que toutes les propriétés obligatoires sont présentes ET renseignées avec des valeurs réelles.
- Ajouter les propriétés recommandées pertinentes — avis, prix, images, durée selon le contexte.
- Publier sur un environnement accessible publiquement, sans blocage robots.txt.
- Vérifier le rendu via Google Rich Results Test après mise en ligne.
- Comparer le balisage avec les éléments effectivement visibles pour l’utilisateur.
- Lancer un crawl Screaming Frog pour vérifier la couverture sur l’ensemble du site.
Chaque étape compense les angles morts de la précédente. Sauter une étape, c’est accepter de ne pas voir une partie des problèmes.
D’ailleurs, trop de sites se contentent d’un schéma « Article » ou « WebPage » par défaut alors qu’un type plus précis aurait déverrouillé des fonctionnalités avancées en SERP. Ce n’est pas un détail — c’est souvent là que se jouent les gains réels.
Ce que j’ai vu sur un site e-commerce réel

Sur un site e-commerce audité récemment, le schéma Product était en place sur toutes les fiches. Schema.org Validator : aucune erreur. Et pourtant, aucune étoile, aucun prix en SERP depuis plusieurs semaines.
En poussant l’analyse avec Google Rich Results Test, le problème est apparu clairement : le champ aggregateRating était présent dans le code, mais systématiquement vide. Le système d’avis n’avait encore recueilli aucune évaluation client. Du coup, la propriété passait les tests techniques — mais n’avait aucune valeur exploitable pour Google. Ni le Validator, ni le crawl n’avaient remonté ce point.
Après avoir collecté des avis sur une dizaine de produits seulement, les étoiles sont apparues en SERP quasi immédiatement. Le taux de clic sur les pages concernées a progressé d’environ 18% le mois suivant. Ce gain était invisible sans l’analyse croisée.
Les erreurs les plus courantes que je relève en audit :
- Propriétés obligatoires présentes mais vides ou identiques sur toutes les pages.
- Type de schéma inadapté, faute de documentation à jour.
- Données structurées dupliquées ou contradictoires entre versions mobile et desktop.
- Blocage robots.txt sur certaines pages, empêchant Googlebot d’accéder au balisage.
Sur ce même site, un crawl Screaming Frog a révélé que 15% des fiches produits n’étaient tout simplement pas balisées — un bug dans le pipeline de génération. Sans audit en masse, personne ne s’en serait rendu compte.
Nuance importante : même après correction, certains rich snippets mettent plusieurs semaines à apparaître. La propagation dépend de Google et de la fréquence de crawl. Patience et vérification régulière restent de mise.
Conclusion
Tester ses données structurées, ce n’est pas une action qu’on fait une fois et qu’on oublie. C’est une discipline à intégrer dans chaque cycle d’évolution du site. Les gains sont réels — et les pertes silencieuses le sont tout autant. En fait, un balisage incorrect ne fait pas de bruit : il prive juste ton site de visibilité, semaine après semaine, sans jamais déclencher d’alerte. La seule façon d’éviter ça, c’est de combiner les outils disponibles, de compléter avec une relecture humaine, et d’en faire une routine de QA à part entière. D’ailleurs, les SERP changent vite : ce qui fonctionnait il y a six mois peut aujourd’hui être ignoré par Google. Intègre la validation Schema.org à ton process de déploiement dès maintenant.
FAQ
Quelle est la différence entre une erreur Schema.org et un avertissement ?
Une erreur signale que la structure ou la valeur d’une propriété ne respecte pas les attendus : le balisage risque d’être ignoré. Un avertissement indique un champ optionnel absent — ça ne bloque pas la reconnaissance du schéma, mais ça limite la richesse du résultat en SERP.
Dois-je corriger tous les avertissements ou seulement les erreurs critiques ?
Les erreurs critiques d’abord, toujours — elles bloquent l’activation du balisage. Du coup, traiter les avertissements ensuite améliore la qualité du rich snippet et peut élargir ta couverture en SERP. D’ailleurs, Google recommande de viser le schéma le plus complet possible.
Peut-on tester Schema.org sans accès à Google Search Console ?
Oui. Rich Results Test, Schema.org Validator et Screaming Frog permettent de valider et d’auditer les données structurées indépendamment. Search Console reste utile pour suivre les impressions et détecter les erreurs remontées après indexation — mais elle n’est pas indispensable pour tester.