
Une balise HTML mal placée, un titre qui saute un niveau, ou un simple oublie… Suffit parfois d’un détail invisible pour que Google passe à côté de votre page. Ça arrive plus souvent qu’on ne le croit. Plusieurs clients m’ont déjà assuré : “Tout est là, pourtant rien ne bouge dans les résultats.” Rien d’alarmant à première vue, pas d’alerte rouge sur l’interface, pourtant l’indexation piétine et la navigation laisse perplexe. Le problème ? Des maladresses dans la structuration HTML.
Ce que je vous propose ici, c’est d’observer ensemble ces erreurs que je croise presque chaque semaine : balises mal employées, hiérarchie bancale, détails qui font décrocher le référencement… L’idée, c’est de comprendre d’abord comment les pages se structurent vraiment, puis de repérer où ça coince, avant d’aborder l’impact direct sur la visibilité et la compréhension par les moteurs.
Comprendre la structure de base d’une page HTML pour éviter les erreurs dès le départ
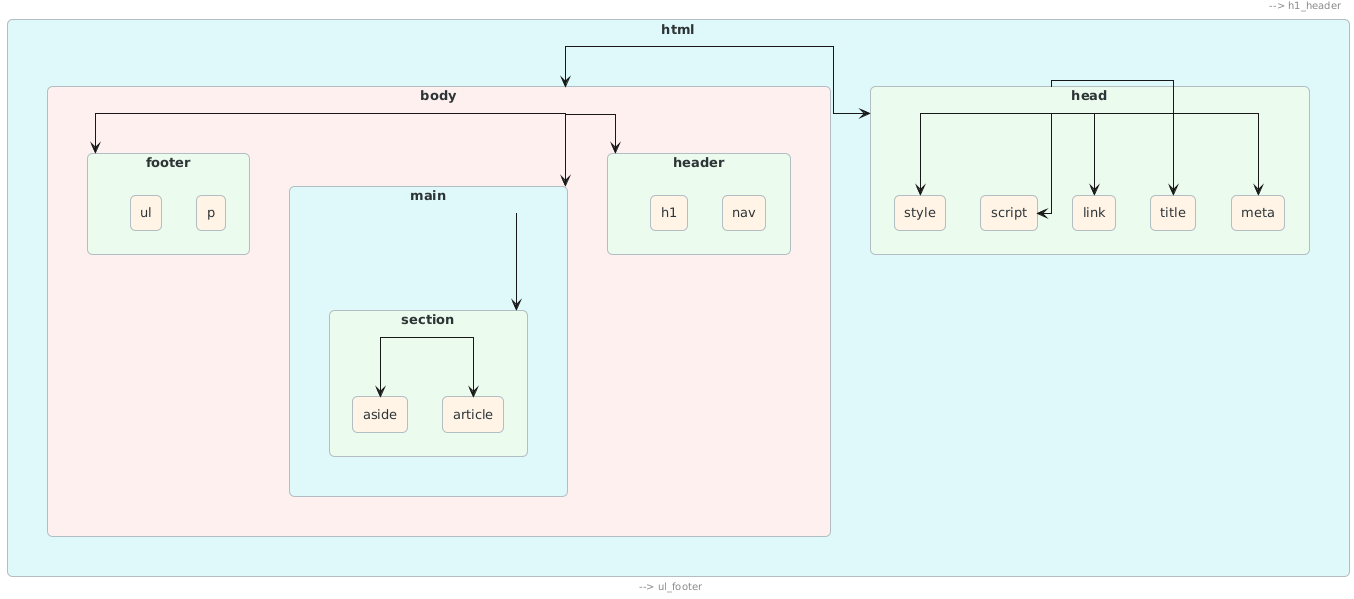
Dans les faits, une page HTML solide se reconnaît d’abord à sa structure. Pas de magie : juste un enchaînement logique d’éléments, imbriqués comme prévu dans la documentation. Tout commence par la balise <html>. Cette racine héberge exactement deux enfants, pas un de plus : <head>, d’un côté, et <body>, de l’autre. Je vois trop souvent des structures bancales; les deux balises ne sont pas interchangeables, encore moins facultatives.
Prenons le <head>. Il n’est pas là pour accueillir votre premier paragraphe ou une bannière, mais bien les coulisses : le <title>, les méta-tags, la déclaration du caractère, vos liens CSS, parfois une font externe. Glisser une image ou du texte visible dans cette section ? Le browser ne se plaint pas toujours, mais le résultat peut surprendre. Sur de vieux navigateurs ou même dans certains crawlers, j’ai vu des balises s’emmêler et l’indexation partir dans tous les sens.
De l’autre côté, le <body> accueille tout ce que l’utilisateur voit : des titres organisés, des paragraphes, des images, les liens qui trament votre navigation. Mais un bogue classique, c’est d’installer ici un script analytique n’importe où, ou d’oublier de bien fermer la balise. Ça penche toujours vers l’imprévu, rarement pour le mieux.
Un point revient presque systématiquement chez les débutants : le casse-tête des titres. Le logo dans une balise <h1>, l’entête du texte en <h3> “parce que c’est plus joli”… Erreur courante. On l’oublie, mais les balises de titre : rien à voir avec la taille ou le gras. Leur mission ? Afficher la structure logique pour les moteurs de recherche et les outils d’accessibilité. On ne saute pas un niveau; chaque titre a son étage dans la maison.
Petit rappel visuel, car un exemple parle toujours plus :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="UTF-8">
<title>Titre de la page</title>
</head>
<body>
<h1>Mon titre principal</h1>
<p>Contenu de la page...</p>
</body>
</html>
Cette toute première ligne, le fameux <!DOCTYPE html>, reste trop souvent négligée. Sans elle ? Le navigateur bascule dans ce qu’on appelle le “quirks mode”. Il essaye alors d’interpréter votre code comme un site vieux de vingt ans… Impossible de savoir précisément ce que Googlebot ou Safari fera avec ça.
Quand on part d’une base solide comme celle-ci, les éventuels soucis sur les balises de contenu deviennent plus simples à détecter. Cette rigueur en amont évite quantité de problèmes en aval.
Les balises principales mal utilisées : <a>, <b> et les listes ordonnées/non ordonnées
À ce stade, une bonne structure ne suffit pas si l’on malmène les balises essentielles. C’est sur ces points qu’on repère souvent des incohérences. Les liens, les mises en forme, les listes : quand c’est mal conduit, le site paraît stable mais perd en sens et en visibilité.
La balise <a> : liens anonymes, problèmes garantis

Rebond direct : on pense trop rapidement qu’un simple lien en <a> suffit. Pourtant, la nature du texte visible est fondamentale. J’ai croisé des pages entières avec des “cliquez ici”, “lien” ou “en savoir plus” pour tout texte d’ancre… Fréquent, surtout sur les anciens blogs ou des pages d’aide rapides.
Pour un utilisateur en navigation clavier, impossible de deviner la destination. Pour un moteur ? L’ancre s’annonce vide de sens. Impossible d’améliorer le référencement sur ces bases. Toujours privilégier une ancre descriptive, du type : <a href="contact.html">Contacter l’équipe</a> ou <a href="rapport.pdf">Télécharger le rapport PDF</a>. Pas besoin d’excentricités. Juste de la précision, pour l’humain comme pour Google.
À noter : une erreur que je retrouve régulièrement sur des sites bricolés à la va-vite : un lien dans un autre lien. HTML5 interdit radicalement cette imbriquation ; certains navigateurs cassent tout le bloc, d’autres le rendent imprévisible… Mieux vaut l’éviter que de se retrouver avec une navigation bancale.
La balise <b> : du gras sans signification

Le réflexe du gras, on l’a tous eu, surtout si on vient du traitement de texte. En HTML, <b> n’exprime qu’un effet visuel, sans la moindre valeur sémantique. Le moteur ne comprend pas que ce mot est crucial; il le voit juste noirci.
Si l’idée c’est de signaler une importance ou une insistance : <strong> prend la relève. Ce point change la donne en SEO et accessibilité. Les personnes malvoyantes, via leur lecteur d’écran, entendent l’insistance associée à <strong>. Dans les pages d’analyse, Google lui accorde parfois un poids supplémentaire.
Même dynamique pour les italiques avec <i> (juste une inclinaison) face à <em> (signalement d’une notion à souligner). On parle d’intention logique : une subtilité qui porte loin, en particulier sur des requêtes de longue traîne ou des pages concurrentielles.
Listes ordonnées ou non : la technique, toujours

Autre habitude glissante : la confusion entre liste ordonnée (<ol>) et non ordonnée (<ul>). L’exemple type : une série de fonctionnalités listée en <ol> alors qu’il n’y a ni progression ni hiérarchie… Cela fausse la compréhension, autant côté lecteur que Google.
Concrètement, on réserve :
<ol>quand l’ordre compte : étapes, recettes, tout où une logique séquentielle s’impose.<ul>pour un simple inventaire : ingrédients, avantages, menu.
Si l’on inverse, la page trompe jusqu’aux technologies d’aide. Un menu principal en liste numérotée ? Pour un robot, cela pourrait évoquer un processus, quand c’est juste une navigation. Sur des sites à fort contenu, ce type d’erreur se répète : au final, l’indexation s’en ressent, tout comme l’ergonomie.
Pourquoi ces erreurs de structuration impactent le référencement de votre page
Après avoir vu comment une mauvaise structuration se glisse dans le code, il faut se pencher sur les conséquences observées. Sur le terrain, les moteurs n’offrent aucune indulgence pour les approximations sémantiques : chaque balise envoie un signal, ou brouille la lecture.
Ce que voient — et lisent — les moteurs de recherche

Pour Googlebot, la page web n’est qu’un code brut. Pas de couleurs, pas d’images, juste un enchaînement logique de structures. Si le <h1> ne donne pas le sujet principal, l’intention reste floue. Les titres sautent d’un <h2> à un <h5> au fil de l’eau ? Résultat : impossible pour le robot de piger le plan réel de la page, ou même le thème dominant.
⚠️ Structuration approximative : Un seul
<h1>par page, descriptif, c’est non négociable. J’ai observé que son absence suffit à faire perdre en thématique. Parfois, entre la première et la troisième page sur une expression très concurrentielle… alors que le contenu était, sur le fond, pertinent.
Les rôles des balises principales sont clairs pour peu qu’on prenne le temps de les étudier dans les pages analysées : <title> pour l’affichage des résultats, <h1> à <h3> pour donner la hiérarchie, texte d’ancre d’un <a> pour indiquer la connexion. Quand chaque pièce est à la bonne place, pas de miracle SEO… mais des fondations sérieuses. L’inverse produit immanquablement du bruit, voire des pages mal (ou pas) indexées.
HTML4 ou HTML5 : évolution du signal sémantique
| Critère | HTML4 | HTML5 |
|---|---|---|
| Balises structurantes | <div>, <span> partout | <header>, <main>, <footer>, <section>, <nav>, <article> |
| Portée sémantique | Pratiquement nulle | Présente, robuste |
| Accessibilité | Souvent superficielle | Intégrée grâce aux attributs ARIA |
| DOCTYPE | Souvent complexe | Unifiée : <!DOCTYPE html> |
La transition d’un site HTML4 vers HTML5 n’a rien de théorique. Encore aujourd’hui, je tombe sur des sites majeurs, tous construits autour de <div> imbriqués, sans aucune balise sémantique. Pour le visiteur, ce n’est pas toujours visible — pour Google, la segmentation disparaît. Les pages modernes, elles, signalent en clair : “Ici le contenu principal”, “voici le menu”, “là le pied de page”. Les crawlers et les assistances techniques gagnent du temps à chaque lecture.
En 2026, s’en remettre uniquement à des <div> sur un projet récent, c’est passer à côté d’informations pourtant gratuites. Ce défaut revient surtout chez ceux qui ont migré dans la précipitation, sans refonte réelle du HTML.
Impact direct sur l’indexation et la compréhension

Sur le plan concret, les erreurs HTML jouent à plusieurs niveaux. Premier maillon : un code mal écrit, balises mal fermées ou imbriquées à l’envers… Le navigateur s’adapte autant qu’il peut, le crawler aussi, mais jamais de façon parfaitement prévisible. Ce qui s’affiche n’est pas toujours ce qui sera indexé.
Vient ensuite la logique thématique. Imaginez : une page sur une marque de chaussures, <h1> absent ou consacré au logo, et les sous-titres partent sur des thématiques sans lien… Google ne classe plus, ou classe très vaguement.
La validation W3C, accessible sur validator.w3.org, expose clairement les erreurs les plus courantes : oublis, balises non fermées, attributs manquants… Je recommande systématiquement ce passage, même avec de l’expérience. C’est rapide, objectif, et détecte les points bloquants bien avant qu’ils ne se transforment en pertes de trafic.Ces erreurs de structure, une fois corrigées, débloquent souvent plus qu’on ne l’attendait. Mais elles ne sont qu’un étage. Performance, crawlabilité, données structurées : si tu veux voir comment tout ça s’articule, c’est là que ça se passe.
Checklist structure minimale :
- [ ] Déclaration
<!DOCTYPE html>présente, tout en haut - [ ] L’attribut
langbien placé sur la balise<html> - [ ] Le
<head>contient au moins<meta charset>et<title> - [ ] Un unique
<h1>, clair, au cœur du sujet - [ ] Titres hiérarchisés sans saut de niveau
- [ ] Les liens
<a>contiennent toujours une ancre descriptive - [ ]
<ol>réservé aux listings où l’ordre compte vraiment - [ ] Code validé par le W3C
Conclusion
Les pièges liés aux balises HTML frappent sans distinction : novices et confirmés passent parfois à côté. Ce ne sont jamais de simples détails. Un <head> incomplet, un <h1> ignoré, des listes en décalage : rien de tout cela ne se remarque aussitôt, mais l’effet sur le classement ou l’accessibilité n’est pas négligeable.
Bonne nouvelle cependant : on avance vite, sans coûteux outils. L’essentiel tient dans le validateur W3C, une relecture à tête reposée, et beaucoup de logique. Si tu débutes, commence par ta page phare, passe-la au peigne fin sur validator.w3.org, corrige une à une les alertes. La progression se suit poste par poste — et c’est là, souvent, qu’on récupère ses premiers points de positions.
FAQ
En quoi HTML5 change-t-il la structuration par rapport à HTML4 ?
HTML4, c’était l’ère du <div>. On créait des sections, des menus, des blocs de contenu… toujours avec des <div>, customisés grâce aux classes, parfois aux identifiants. HTML5 rebat les cartes : les zones logiques disposent de balises précises. <header>, <main>, <footer>, <section>, <nav>, <article> indiquent dès la racine à quoi sert chaque pan. Plus besoin de tricher. Pour Google et les aides techniques : l’analyse se fait plus vite, de façon standard.
Comment vérifier et valider facilement son code HTML aujourd’hui ?
La validation W3C reste le réflexe pratique. L’outil, disponible gratuitement sur validator.w3.org, offre trois modes : coller tout son code, déposer une URL, ou glisser son fichier HTML. Chaque anomalie détectée s’affiche, parfois avec une suggestion de correction. Rien de sorcier, mais ça fait gagner un temps fou sur les problèmes de structure, et je l’utilise encore en audit quand je flaire une anomalie de classement.