
Tu publies une page. Elle disparaît dans le vide pendant des jours, parfois des semaines. Tes concurrents apparaissent sur les mêmes requêtes. Toi, rien. Chercher des solutions rapides à une indexation Google lente, c’est légitime — mais avant d’agir, il faut comprendre pourquoi ça bloque. Et la réponse n’est presque jamais la même d’un site à l’autre.
Sites neufs ou domaines bien établis : personne n’est à l’abri. Ce qui change, c’est la nature du frein. Contenu trop mince, serveur lent, maillage interne inexistant, sitemap mal configuré — l’origine du problème détermine la solution. Ce que je vois régulièrement dans mes diagnostics : on agit trop vite, sur la mauvaise chose, sans avoir observé les signaux disponibles.
Ce guide ne propose pas de recette miracle. Il propose une lecture méthodique des vrais leviers — dans l’ordre où ils comptent.
Pourquoi Google n’indexe plus tes pages aussi vite
Beaucoup de sites bien configurés attendent quand même plusieurs semaines avant de voir leurs pages apparaître dans les SERP. C’est contre-intuitif, et pourtant logique.
L’indexation dépend du contexte global de ton domaine. Googlebot ne traite pas toutes les URLs de la même façon. Un site avec des erreurs HTTP qui s’accumulent, un historique instable ou un contenu qui change sans logique éditoriale claire — Google le traite avec prudence. Ce n’est pas une sanction. C’est de la gestion de ressources.
Le budget de crawl, c’est exactement ça : la quantité de ressources que Google accepte d’investir sur ton site. Si ce budget est faible et que tu publies massivement, les nouvelles pages attendent. Google décide de l’ordre. Point. Tu ne peux pas forcer cette file d’attente, seulement améliorer ta position dedans.
Autre signal souvent sous-estimé : la confiance algorithmique. Plus un domaine accumule des backlinks sérieux, un contenu utile et une technique propre, plus Google a intérêt à indexer rapidement ce qu’il publie. Ces deux dernières années, avec la multiplication des contenus générés par IA, Google est devenu franchement plus sélectif. L’indexation n’est plus automatique. Elle se mérite.
Ton sitemap XML envoie peut-être les mauvais signaux
Paradoxalement, un sitemap mal construit peut ralentir l’indexation au lieu de l’accélérer.
C’est le premier point de contact entre ton site et Google. Si ce fichier contient des URLs en 404, des pages en noindex ou des chemins en double, Google reçoit un signal de gestion approximative. Il va crawler moins, pas plus.
Deux balises font souvent l’objet d’erreurs concrètes : <changefreq> et <priority>. Surévaluer la fréquence de mise à jour pour toutes tes pages, c’est comme crier au loup. Google le sait. Résultat : il ignore ces indications. Hiérarchise. Tes pages stratégiques méritent un <priority> à 0.8 ou 1. Tes mentions légales, 0.3 suffit.
| Erreur de sitemap | Impact sur l’indexation | Recommandation |
|---|---|---|
| URL 404 dans sitemap | Gaspillage de budget de crawl | Supprimer ou corriger |
| Pages noindex incluses | Confusion sur l’intention | Retirer du sitemap |
| URLs en HTTP | Risque de duplication | Uniformiser en HTTPS |
| Ancien format XML | Problème de lecture Googlebot | Mettre à jour le format |
Vérifie ton sitemap dans Google Search Console. Surveille le ratio URLs valides / URLs retirées. Un sitemap propre ne garantit pas l’indexation rapide, mais un sitemap sale la ralentit à coup sûr.
Google Search Console : l’outil d’indexation manuelle et ses limites

Corriger le sitemap est une chose — mais si une page est bloquée, il faut aussi agir directement.
L’outil d’inspection d’URL dans Search Console reste, en 2026, le levier le plus direct pour déclencher un crawl. Tu vérifies si la page est indexée, tu identifies les blocages éventuels (robots.txt, erreurs d’exploration), et tu peux demander manuellement à Googlebot de passer.
Attention. Cette demande n’est pas un passe-droit. Elle fonctionne bien quand la page est techniquement propre, le contenu original, et l’intent clairement satisfait. Si tu soumets une page avec du contenu dupliqué ou trop mince, la demande d’indexation ne change rien. Google indexe ce qu’il juge utile.
Pour les sites avec de nombreuses mises à jour, soumettre un sitemap actualisé vaut mieux que de traiter les URLs une par une. Ça évite de saturer le quota quotidien.
Enfin, si une page reste en statut « explorée, mais non indexée » après 72 heures malgré la procédure — le problème n’est pas technique. C’est un signal de qualité ou de confiance. C’est là que beaucoup de gens s’arrêtent trop tôt dans leur diagnostic.
Les erreurs d’exploration qui paralysent Googlebot
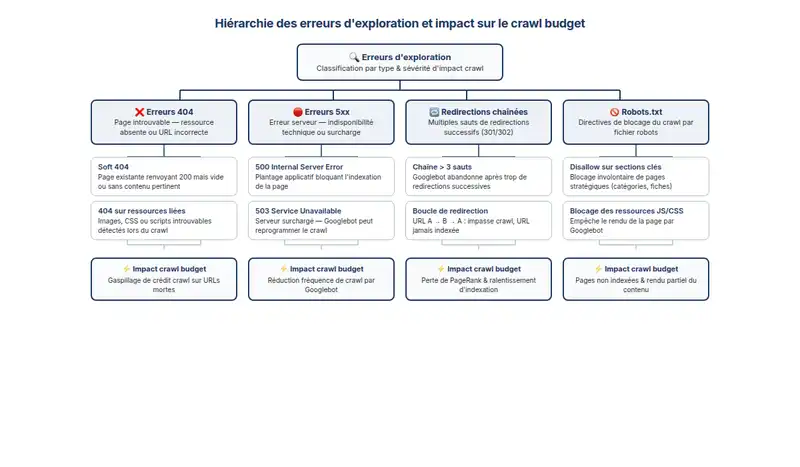
Même si tu n’as jamais touché à ton robots.txt, quelque chose peut bloquer ton crawl sans que tu le voies.
Les erreurs 404 isolées ne posent pas de problème en soi. En revanche, quand elles s’accumulent sur des pages stratégiques ou des sections entières, elles consomment le budget de crawl sans rien produire. Les erreurs 5xx sont encore plus problématiques : elles signalent un serveur instable, et Google va progressivement réduire la fréquence de ses passages.
Les redirections chaînées, c’est un classique que je vois sur presque tous les sites migrés en catastrophe. Une URL qui redirige vers une autre, elle-même redirigée, ça fatigue Googlebot. Il abandonne souvent avant d’atteindre la destination. Une seule étape de redirection, pas plus.
Le fichier robots.txt mal configuré, lui, peut bloquer un site entier avec une seule ligne. Un Disallow: / placé malencontreusement, et Googlebot ne passe plus nulle part. Ce genre d’erreur arrive plus souvent qu’on ne le croit lors des refondtes techniques ou des migrations. Valide toujours la configuration dans l’outil dédié de Search Console avant de mettre en ligne.
Lis tes rapports de crawl régulièrement. Chaque anomalie non corrigée s’accumule et finit par affecter l’ensemble du domaine.
Ce que ton contenu doit contenir pour être indexé vite

Un site techniquement propre n’est pas suffisant si Google considère que tes pages n’apportent rien.
C’est un constat que j’observe de plus en plus depuis l’accélération de la production de contenu IA : beaucoup de pages sont explorées, mais jamais indexées. Pas parce qu’elles sont bloquées. Parce qu’elles ne méritent pas d’être indexées, selon les critères actuels de Google.
La profondeur de traitement est centrale. Une page qui reprend les mêmes angles que les vingt premiers résultats, sans aller plus loin, risque de rester en attente. À l’inverse, un contenu qui développe vraiment le sujet — avec des exemples, des angles originaux, des données récentes — envoie un signal fort. J’ai observé sur un site éditorial qu’en passant d’articles de 300 à plus de 1 200 mots traitant l’ensemble des angles d’une requête, le délai d’indexation moyen chutait de dix jours à moins de 48 heures.
La correspondance avec l’intention de recherche est tout aussi critique. Trop d’articles ratent leur cible : ils parlent du sujet sans répondre à ce que l’utilisateur cherche vraiment.
Compare dans Search Console les pages explorées non indexées avec tes pages bien indexées. La différence de longueur, de fraîcheur et de structure te donnera souvent toutes les réponses dont tu as besoin.
Maillage interne : le levier le plus sous-estimé
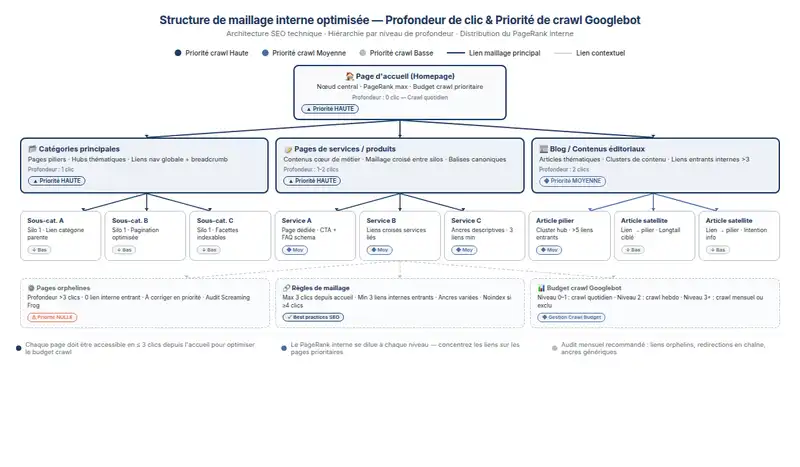
Un contenu bien rédigé sur une page orpheline attendra longtemps. C’est aussi simple que ça.
Le maillage interne conditionne la façon dont Googlebot navigue sur ton site. Une nouvelle page qui ne reçoit aucun lien interne — accessible uniquement via le sitemap ou une URL directe — sera découverte en dernier. Une page intégrée dans les catégories principales, les menus et les articles existants sera poussée naturellement vers le robot.
La profondeur de clic depuis la page d’accueil a un effet concret. Au-delà de trois clics, la fréquence de crawl diminue significativement. Revoir ta structure de navigation est souvent le levier le plus rentable pour accélérer l’indexation des nouveaux contenus.
Les ancres comptent aussi. Une ancre générique comme « cliquez ici » n’aide ni l’utilisateur ni Google. Une ancre contextuelle, reflet du sujet réel de la page cible, améliore la compréhension sémantique — surtout sur des sujets concurrentiels.
Sur un blog mis à jour quotidiennement, j’ai observé qu’ajouter un lien vers des pages orphelines dans chaque nouvel article avait réduit le délai moyen d’indexation de 72 à 18 heures. Le maillage interne, piloté régulièrement, c’est du budget de crawl récupéré gratuitement.
Performance serveur : un frein que peu de gens diagnostiquent
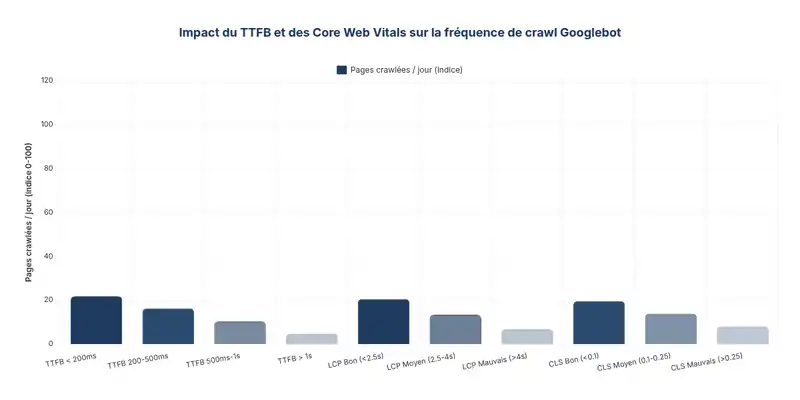
Même si ton contenu est excellent et ton maillage propre, un serveur lent peut tout ralentir.
Le Time To First Byte (TTFB) est le premier indicateur à vérifier. Un serveur qui met plus d’une seconde à répondre pousse Googlebot à espacer ses passages. Il ne va pas attendre indéfiniment. À l’inverse, un TTFB inférieur à 500 ms permet un crawl plus fluide et plus fréquent.
Les Core Web Vitals entrent aussi dans l’équation. Un LCP inférieur à 2,5 secondes est associé à un crawl plus régulier de la part de Google. Ce n’est pas anecdotique : Google interprète les métriques de performance comme un signal de santé globale du site.
La disponibilité du serveur, elle, est souvent négligée. Chaque timeout détecté lors d’une tentative de crawl retarde l’indexation. Sur un hébergement mutualisé sous-dimensionné, les pics de trafic — lors d’un lancement ou d’une campagne — peuvent créer exactement ce type d’incident. Surveille tes logs serveur en parallèle des rapports Search Console. Tu repères vite les corrélations entre indisponibilité et baisse de fréquence de crawl.
Si la situation se répète, la migration vers un hébergement mieux calibré n’est plus une option : c’est une nécessité.
Conclusion
Accélérer l’indexation, ça commence toujours par éliminer ce qui bloque : erreurs HTTP, robots.txt mal configuré, sitemap approximatif, serveur trop lent. Ce sont les fondations. Ensuite, tu utilises Search Console pour soumettre tes pages et tu surveilles pendant 48 à 72 heures.
Si le délai reste anormal malgré tout ça, arrête de chercher un problème technique. Le vrai frein, à ce stade, c’est la confiance que Google accorde à ton site. Et ça ne se règle pas avec un outil : ça se construit avec de la cohérence éditoriale, un maillage interne solide, et des signaux d’autorité externes. Pas en une semaine.
Commence par lire le rapport « Pages explorées, non indexées » dans ta Search Console. Ce rapport te dira, sans ambiguïté, où Google a décidé de s’arrêter.
FAQ
Comment Google décide-t-il quelles pages crawler en premier ?
Google privilégie les pages avec les meilleurs signaux de fiabilité : liens internes forts, contenus régulièrement mis à jour, absence d’erreurs techniques, et historique positif dans la Search Console.
Les backlinks accélèrent-ils vraiment l’indexation ?
Oui. Des liens entrants de qualité, issus de sites déjà bien indexés, peuvent déclencher directement un passage de Googlebot et favoriser l’indexation rapide de nouvelles pages.