On croit souvent qu’en SEO optimisation technique, l’essentiel se joue sur le contenu. Publie régulièrement, couvre le sujet mieux que tes concurrents, et Google finira par te récompenser. C’est une vision séduisante — et elle explique pourquoi autant de sites stagnent malgré des contenus solides. La réalité que j’observe depuis quinze ans : un contenu excellent sur une base technique défaillante, c’est un bon livre dans une bibliothèque dont les portes sont fermées à clé.
Ce guide couvre trois axes — architecture technique, performance utilisateur, crawlabilité — avec des critères concrets, une checklist opérationnelle, et les erreurs que je vois revenir systématiquement d’un audit à l’autre.
Fondamentaux de l’Architecture Technique SEO
Commence toujours par là. Pas par les images, pas par les métadonnées, pas par le sitemap. L’architecture technique conditionne tout ce qui vient ensuite — si elle est bancale, aucune optimisation de surface ne compensera.
Structure des URLs : clarté, cohérence, et signal sémantique

L’URL est le premier signal que Googlebot reçoit quand il arrive sur une page. Avant même d’en lire le contenu. Une URL propre et lisible sert simultanément l’utilisateur et le moteur de recherche. À l’inverse, une URL dynamique chargée de paramètres — ?id=4521&session=abc&ref=newsletter — dilue la pertinence thématique de la page et ouvre la porte aux problèmes de contenu dupliqué.
Critères d’une URL techniquement saine :
- Minuscules uniquement, sans espaces ni caractères spéciaux non encodés
- Séparateurs en tirets (
-), jamais en underscore (_) — Google lui-même a confirmé que cette distinction est pertinente - Aucun paramètre superflu en production
- Profondeur de répertoire raisonnée : trois niveaux maximum pour les pages stratégiques
- Redirections 301 cohérentes en cas de changement de structure
L’erreur que je vois le plus souvent dans ce registre : une migration CMS sans redirections permanentes. Un site passe de WordPress à Webflow, les URLs changent, et personne ne mapple l’ancienne structure vers la nouvelle. Le résultat arrive dans les semaines qui suivent — erreurs 404 en cascade, autorité accumulée page par page qui part à la poubelle, désindexation progressive des contenus les plus anciens.
La canonicalisation est indissociable de la gestion des URLs. Chaque page doit avoir une balise <link rel="canonical"> qui pointe vers sa version de référence. Sur les sites e-commerce, le filtrage par attributs génère naturellement des centaines de variantes URL — sans canonical correctement configurée, c’est du contenu dupliqué non maîtrisé.
Balisage HTML : la grammaire que lisent les moteurs de recherche

Le balisage HTML, beaucoup le traitent comme une formalité. En pratique, c’est le langage par lequel un site communique sa structure aux robots d’indexation. Un balisage défaillant, c’est comme soumettre un dossier désorganisé : l’information est peut-être là, mais elle est inexploitable.
Le <h1> doit apparaître une seule fois par page, intégrer le mot-clé primaire, et correspondre réellement au sujet traité. Les <h2> et <h3> structurent la hiérarchie du contenu de façon logique. L’utilisation de balises heading pour des raisons purement stylistiques — parce que le graphiste voulait du texte plus grand — prive le moteur d’un repère fondamental.
Les balises <title> et <meta description> sont ce que Google affiche en priorité dans les SERPs. Un <title> tronqué, dupliqué, ou absent affecte directement le taux de clic. La méta description n’est pas un facteur de ranking direct, mais elle influence l’attractivité du résultat — et par ricochet, les signaux comportementaux qui remontent à Google.
Les attributs alt sur les images remplissent deux fonctions : l’accessibilité pour les utilisateurs en situation de handicap visuel, et la compréhension du contenu visuel par les moteurs qui ne voient pas les images. Un alt vide ou générique comme alt="image1" est une opportunité manquée à chaque fois. Ces erreurs de balisage, je les croise sur presque tous les audits. Si tu veux comprendre d’où elles viennent et pourquoi elles coûtent des positions, cet article les passe en revue une par une — avec à chaque fois ce que ça donne concrètement côté indexation.
Méta-données : entre unicité et pertinence
Presque tous les audits que j’ai réalisés révèlent les mêmes problèmes de méta-données : des <title> dupliqués sur plusieurs pages, des méta descriptions absentes sur les pages de catégorie, ou des descriptions identiques générées automatiquement par le CMS sur des dizaines de pages en même temps.
Chaque page stratégique doit avoir un <title> unique d’environ 60 caractères, et une méta description unique de 150 à 160 caractères maximum. Ces valeurs ne sont pas arbitraires — elles correspondent aux seuils d’affichage de Google, au-delà desquels le texte est coupé avec des points de suspension dans les SERPs.
Règle d’interprétation n°1 : Des méta-données dupliquées sur plus de 10 % des pages indexées d’un site, c’est un signal d’alerte. En dessous de ce seuil, il s’agit souvent de pages de faible valeur que la canonicalisation ou une directive
noindexdoit gérer en priorité.
Les robots meta tags méritent une vérification systématique. Lors d’un audit, il n’est pas rare de trouver des pages stratégiques portant accidentellement la directive noindex — une manipulation malencontreuse dans le CMS, un plugin mal configuré. C’est un problème silencieux : aucune erreur visible, aucune alerte, juste des pages qui disparaissent progressivement de l’index.
Performance et Expérience Utilisateur
Maîtriser l’architecture technique, c’est nécessaire. Mais ça ne suffit pas si la page met quatre secondes à s’afficher. Depuis l’intégration des signaux d’expérience dans l’algorithme Google, la performance n’est plus un bonus — c’est une condition d’entrée dans la compétition pour les premières positions.
Vitesse de chargement : au-delà du simple chronomètre

La vitesse de chargement est probablement la métrique la plus citée et la plus mal comprise en SEO technique. Beaucoup de praticiens fixent leur attention sur le score PageSpeed Insights comme s’il s’agissait d’une note scolaire à maximiser coûte que coûte. C’est une erreur de perspective.
Ce qui compte, c’est la perception de la vitesse par l’utilisateur, pas le temps de chargement total de la page. Une page qui affiche son contenu principal rapidement mais charge lentement ses éléments secondaires sera perçue comme rapide. Une page qui bloque le rendu trois secondes pour charger un script tiers sera perçue comme lente, même si son temps total est comparable.
Les leviers techniques d’amélioration sont multiples :
- Compression des ressources : activation de Gzip ou Brotli au niveau serveur, minification des fichiers CSS, JavaScript, et HTML
- Optimisation des images : formats modernes (WebP, AVIF), dimensionnement adapté aux breakpoints, attribut
loading="lazy"pour les images hors-champ initial - Stratégie de cache : paramétrage précis des headers
Cache-ControletExpirespour les ressources statiques - Réduction des requêtes HTTP : fusion des fichiers CSS, élimination des scripts inutilisés, utilisation de sprites SVG
- Hébergement : le TTFB (Time To First Byte) est souvent le facteur le plus négligé. Un hébergement sous-dimensionné plafonne toutes les autres optimisations, quels que soient les efforts consentis par ailleurs
Un audit de vitesse doit être conduit séparément sur mobile et desktop — les performances divergent significativement en fonction du rendu moteur et de la bande passante simulée.
Core Web Vitals : les métriques qui comptent maintenant
Les Core Web Vitals sont devenus, depuis leur intégration dans le ranking de Google en 2021, le référentiel commun de la performance web. Trois métriques principales :
| Métrique | Ce qu’elle mesure | Seuil « Good » |
|---|---|---|
| LCP (Largest Contentful Paint) | Vitesse d’affichage de l’élément principal | ≤ 2,5 secondes |
| INP (Interaction to Next Paint) | Réactivité aux interactions utilisateur | ≤ 200 ms |
| CLS (Cumulative Layout Shift) | Stabilité visuelle de la page | ≤ 0,1 |
Google a progressivement remplacé le FID par l’INP comme métrique de réactivité, ce qui a modifié les priorités d’optimisation pour les sites riches en interactions JavaScript.
Ce que ces métriques indiquent concrètement :
Un LCP dégradé pointe généralement vers une image héro non optimisée, un serveur lent, ou du CSS bloquant le rendu. Un CLS élevé vient souvent des publicités, des polices de caractères chargées asynchronement sans réservation d’espace, ou d’iframes injectées dynamiquement. Un INP dégradé révèle des problèmes de JavaScript avec des tâches longues qui monopolisent le thread principal.
Pour mesurer tout ça : la Google Search Console (rapport Expérience de la page), complétée par le Chrome User Experience Report (CrUX) pour les données terrain, et Lighthouse pour les données de laboratoire. La distinction entre données terrain et données simulées est fondamentale — seules les données terrain alimentent le ranking.
Sécurité HTTPS : un prérequis, pas un avantage compétitif

HTTPS est un facteur de ranking confirmé par Google depuis plusieurs années. En 2025, se demander « faut-il passer en HTTPS ? » serait une question hors époque. La vraie question est : est-ce que l’implémentation est correcte ?
Les problèmes courants qu’un audit de sécurité met en lumière :
- Mixed content : des ressources (images, scripts, CSS) encore chargées en HTTP sur un site en HTTPS. Les navigateurs bloquent ou avertissent sur ces ressources, ce qui dégrade l’expérience et la confiance de l’utilisateur.
- Certificat expiré ou mal configuré : un certificat SSL invalide provoque des avertissements bloquants dans le navigateur. Le taux de rebond qui suit est massif.
- Redirections incomplètes : HTTP redirige vers HTTPS, mais les URLs internes ou les sitemaps référencent encore des URLs en HTTP.
- Absence de HSTS : le HTTP Strict Transport Security force le navigateur à utiliser HTTPS pour toutes les requêtes futures. Sans lui, le site reste exposé aux attaques de downgrade.
🚨 Red Flag : Si un audit révèle que des pages stratégiques — accueil, catégories principales, articles à fort trafic — restent accessibles en HTTP sans redirection automatique vers HTTPS, c’est une priorité absolue avant toute autre correction.
Stratégies Avancées de Crawlabilité et Indexation
Résoudre l’architecture et la performance, c’est poser les fondations. Mais à quoi ça sert si Googlebot ne peut pas explorer correctement le site, ou si les pages importantes ne sont jamais indexées ? Cette partie traite des mécanismes qui gouvernent la relation entre un site et les robots des moteurs de recherche.
Indexation : contrôler ce que Google voit
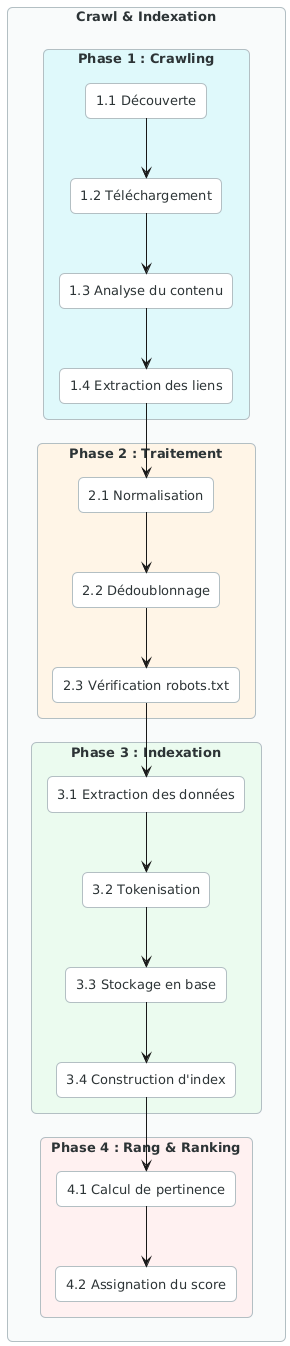
Une distinction que beaucoup négligent : « être crawlé » et « être indexé » sont deux étapes distinctes. Une page peut être visitée par Googlebot sans être intégrée à l’index. Confondre les deux conduit à des diagnostics erronés.
Les leviers de contrôle de l’indexation :
robots.txt peut quand même être indexée si des liens externes pointent vers elle. C’est une instruction de crawl, rien de plus.
La balise <meta name="robots" content="noindex"> est l’outil pour exclure explicitement une page de l’index. Utile pour les pages de tags, les résultats de recherche interne, les pages de confirmation de commande, et toutes les pages à faible valeur SEO.
Le sitemap XML est la carte fournie à Googlebot pour lui signaler les pages à explorer en priorité. Un sitemap mal entretenu — avec des URLs en 404, des pages en noindex, ou des pages canonicalisées ailleurs — est contre-productif. Il doit être soumis dans la Google Search Console et mis à jour automatiquement à chaque publication.
Le budget de crawl est la quantité de ressources que Googlebot alloue à l’exploration d’un site sur une période donnée. Sur les sites de grande taille, chaque URL dupliquée, chaque page de faible valeur crawlée est une ressource gaspillée — du budget consommé au détriment des pages stratégiques.
Règle d’interprétation n°2 : Sur un site de moins de 1 000 pages bien structurées, le budget de crawl n’est généralement pas un facteur limitant. Au-delà de 10 000 pages, ou sur tout site générant massivement des URLs dynamiques, c’est un axe d’optimisation prioritaire à intégrer dans l’audit.
Maillage interne : l’architecture de la pertinence
Le maillage interne est probablement le levier le plus sous-exploité du SEO technique. Il détermine comment le PageRank — l’autorité d’une page — se distribue au sein du site, et comment les robots perçoivent la hiérarchie thématique des contenus.
Un maillage interne défaillant se manifeste de plusieurs façons :
- Pages orphelines : aucun lien interne ne pointe vers elles. Googlebot les découvre rarement, et leur autorité est nulle puisqu’aucun flux de PageRank ne les alimente.
- Maillage trop profond : des pages importantes enfouies à cinq ou six clics de l’accueil. Plus une page est éloignée, plus son autorité reçue est diluée.
- Anchor texts génériques : des liens dont le texte d’ancre est systématiquement « cliquez ici » ou « en savoir plus » ne transmettent aucun signal sémantique sur la page de destination.
- Suroptimisation : à l’inverse, des textes d’ancre systématiquement optimisés avec le mot-clé exact peuvent sonner artificiel. La diversité des ancres est un signal de naturalité.
La stratégie efficace repose sur les topic clusters : une page pilier à haute autorité, sur un sujet large, reliée par des liens contextuels bidirectionnels à des pages satellites plus granulaires. Cette architecture favorise à la fois la compréhension sémantique par Google et la navigation utilisateur.
Pour auditer le maillage interne : Screaming Frog, Sitebulb, ou Ahrefs Site Audit permettent de visualiser la distribution des liens internes, d’identifier les pages orphelines, et de mesurer la profondeur de chaque page depuis la racine.
Données structurées : parler le langage des moteurs de recherche

Les données structurées (Schema.org) permettent de fournir aux moteurs de recherche des informations contextuelles enrichies sur le contenu d’une page. Elles ne remplacent pas le contenu — elles le complètent et permettent d’obtenir des rich snippets dans les SERPs : étoiles, prix, dates, FAQ, fils d’Ariane.
L’impact sur le taux de clic peut être significatif, bien que leur effet sur le ranking lui-même reste indirect. Un résultat visuellement plus riche capte davantage l’attention et génère plus de clics à position équivalente.
Les types Schema.org les plus pertinents selon les typologies de sites :
- Article / BlogPosting : contenus éditoriaux, blogs, guides
- FAQPage : pages incluant des questions-réponses — peut générer des entrées FAQ dans les SERPs
- BreadcrumbList : fils d’Ariane, améliore la compréhension de la structure du site
- Organization / LocalBusiness : entités locales ou institutionnelles
- HowTo : tutoriels et guides étape par étape
- Review / AggregateRating : avis et notes
Les erreurs fréquentes dans l’implémentation :
- Balisage ne correspondant pas au contenu visible : Google pénalise le balisage trompeur. Si la page ne contient pas de FAQ visible, le balisage FAQPage constitue une infraction aux directives.
- Syntaxe incorrecte : des erreurs JSON-LD ou microdata empêchent le traitement correct du balisage. Le Rich Results Test de Google doit être utilisé systématiquement pour valider avant publication.
- Duplication de types : baliser plusieurs fois le même type sur une page peut créer des conflits d’interprétation.
Adaptation aux CMS spécifiques : WordPress, Shopify, et les autres

Les problèmes techniques ne se manifestent pas de la même façon selon le CMS utilisé. C’est une dimension que beaucoup de guides ignorent — pourtant elle conditionne la faisabilité et la priorité des corrections.
WordPress est le CMS le plus répandu, et ses problèmes techniques sont prévisibles : prolifération de pages de tags et d’auteurs non canonicalisées, génération automatique de flux RSS parasites, conflits entre plugins SEO (Yoast, Rank Math, SEOPress), ralentissements causés par des plugins tiers mal optimisés. Un audit WordPress doit systématiquement vérifier les réglages d’indexation dans Réglages > Lecture — j’ai vu des sites entiers en noindex depuis des mois sans que personne ne s’en soit aperçu.
Shopify impose des contraintes structurelles plus rigides. La structure des URLs est partiellement imposée (/products/, /collections/, /pages/), et la gestion des canoniques pour des produits appartenant à plusieurs collections demande une attention particulière. La canonical par défaut de Shopify pointe vers l’URL de collection la plus récente, ce qui peut créer des incohérences non triviales. Les scripts d’application injectés via les app blocks impactent également les Core Web Vitals de façon parfois significative.
Webflow génère un code HTML propre par construction, mais souffre parfois de problèmes de redirections quand les structures de pages CMS sont modifiées. La gestion des sitemaps reste limitée pour les sites complexes, et la configuration des redirections via l’interface Webflow est fonctionnelle mais peu scalable pour les migrations importantes.
Tout CMS headless — Next.js, Nuxt, Gatsby avec un backend Contentful ou Strapi — introduit des problèmes spécifiques liés au rendu JavaScript. Le Server-Side Rendering (SSR) ou la Static Site Generation (SSG) doivent être correctement configurés pour garantir que les robots reçoivent du HTML pré-rendu, et non une coquille JavaScript vide. Un audit de site headless commence obligatoirement par une vérification du rendu via l’outil d’inspection d’URL dans la Google Search Console.
Checklist d’audit technique SEO opérationnelle
Une checklist structurée par priorité pour conduire un audit technique complet. Elle couvre les points de blocage les plus fréquents et les plus impactants — pas l’exhaustivité théorique, mais ce qui compte dans la pratique.
Priorité 1 — Critique (à corriger immédiatement)
- [ ] Site accessible en HTTPS, redirection HTTP → HTTPS active sur toutes les pages
- [ ] Aucune page stratégique en
noindexinvolontairement - [ ] Fichier
robots.txtne bloquant pas les ressources critiques (CSS, JS) - [ ] Aucune erreur 404 sur les pages recevant des backlinks
- [ ] Balise
<h1>unique par page, présente sur toutes les pages stratégiques - [ ] Sitemap XML soumis dans la Google Search Console, sans URLs en erreur
Priorité 2 — Important (à traiter dans les 30 jours)
- [ ] Balises
<title>et<meta description>uniques sur toutes les pages indexées - [ ] Structure des URLs propre, sans paramètres parasites dans l’index
- [ ] Canoniques correctement configurées sur les pages à contenu similaire
- [ ] Core Web Vitals dans le vert pour les pages prioritaires (LCP ≤ 2,5s, CLS ≤ 0,1)
- [ ] Attributs
altprésents et pertinents sur les images - [ ] Aucune page orpheline sur les contenus stratégiques
Priorité 3 — Optimisation (à intégrer dans la roadmap)
- [ ] Données structurées Schema.org implémentées et validées
- [ ] Maillage interne optimisé avec topic clusters identifiés
- [ ] Budget de crawl analysé et protégé si site > 10 000 pages
- [ ] HSTS configuré au niveau serveur
- [ ] Images converties en WebP ou AVIF
- [ ] Scripts tiers chargés en mode
deferouasync
Conclusion
Un audit SEO technique n’est pas un événement ponctuel. C’est un processus continu — un site évolue, le CMS est mis à jour, des plugins sont ajoutés, des contenus sont publiés en masse. Les trois axes couverts ici forment un système interdépendant : corriger l’un sans traiter les autres produit des résultats partiels, souvent décevants.
La logique de priorisation est simple : commence par les problèmes qui bloquent l’indexation ou dégradent massivement l’expérience. Puis travaille la performance. Puis les enrichissements sémantiques. Cette séquence suit l’impact décroissant par effort investi — elle n’est pas arbitraire.
Aucun outil n’automatise le jugement. Les crawlers détectent ; c’est l’expertise qui priorise et corrige. Lance cette checklist aujourd’hui, et reviens vérifier l’état de l’indexation dans la Google Search Console dans les 60 jours qui suivent.
FAQ
Source : Vidéo recommandée
Quelle est la fréquence recommandée pour un audit SEO technique ?
Un audit complet est recommandé au minimum une fois par an pour les sites stables, et après chaque migration, refonte, ou mise à jour CMS majeure. Pour les sites e-commerce ou à forte vélocité de contenu, un audit partiel trimestriel sur les métriques critiques — indexation, Core Web Vitals, erreurs d’exploration — est une bonne pratique.
Les Core Web Vitals sont-ils vraiment un facteur de ranking significatif ?
Oui, mais leur poids relatif reste difficile à isoler des autres signaux. Google a confirmé qu’ils font partie du système de ranking depuis 2021. En pratique, leur amélioration a un impact direct sur le taux de clic et le taux de rebond — deux signaux comportementaux que Google intègre dans son évaluation. L’amélioration des Core Web Vitals est donc doublement bénéfique : directement via le ranking, indirectement via les signaux utilisateurs.
Comment prioriser les corrections quand les ressources sont limitées ?
Applique le principe de l’impact maximal pour l’effort minimal. Les problèmes d’indexation — pages noindex erronées, robots.txt bloquant — ont un impact immédiat et ne demandent généralement que quelques minutes à corriger. Les problèmes de performance demandent plus d’effort mais génèrent des gains mesurables. Les données structurées et le maillage avancé constituent la troisième vague, à traiter quand les fondations sont stables.
Un site avec un bon score PageSpeed est-il forcément bien optimisé techniquement ?
Non. PageSpeed Insights mesure des métriques de performance mais ne détecte pas les problèmes d’indexation, de canonicalisation, de maillage interne, ou de données structurées. Un site peut afficher un score de 90+ et avoir des dizaines de pages stratégiques non indexées, ou des duplicates de contenu non maîtrisés. L’audit technique est bien plus large que la seule performance de chargement.
Les données structurées peuvent-elles nuire au référencement si elles sont mal implémentées ?
Un balisage Schema.org trompeur — ne correspondant pas au contenu réellement visible sur la page — peut entraîner une action manuelle de Google. En pratique, les erreurs de syntaxe sont plus fréquentes que les infractions intentionnelles, et elles ne provoquent pas de pénalité : Google ignore simplement le balisage. La validation via le Rich Results Test avant chaque publication n’est pas optionnelle.
Doit-on gérer différemment l’audit technique selon la taille du site ?
Oui, substantiellement. Sur un site de moins de 500 pages, l’audit peut être réalisé avec un outil de crawl basique et une inspection manuelle. Au-delà de 10 000 pages, la gestion du budget de crawl, la segmentation du sitemap, et l’automatisation des contrôles qualité deviennent indispensables. Les sites à très grande échelle nécessitent souvent du monitoring en continu plutôt que des audits ponctuels — un audit annuel sur un site de 500 000 pages, ça ne suffit pas.